Notes
Usually in data modeling-related tickets like this, to reproduce, we require:
- The how-to question.
- The dataset schema (which model, relationships, available dimensions/metrics).
- The expected AQL explore.
Usually in debugging a dbt test warning/failure:
- The error / signal.
- Which model? What are upstream models (to know the root cause can come from) and downstream models (to know affected models)?
- Query real data.
- Find out root cause. This may vary not only one root cause but many.
- Categorize root causes:
- Data pipeline side
- Source side
- Some common questions:
- The test is testing what behavior? What does the test expect and not expect?
- If we don’t feel the test make sense, question why is it there from first day?
In [[Oxygen Not Included]], there is a DLC that introduces a new kind of labor: Bionic Dupes.
- It’s like introducing robots into the types of labor, beside native dupes.
- https://media.secondbrain.lelouvincx.com/2026/03/6254fbf630764a4fe494a585a5b99d4d.png
- The robots come with some advantages:
- Consume less oxygen
- Survive better in harsh environment
- But disadvantages:
- A lot of power energy
- Extract gunk / waste water
- With those disadvantages, hard to say we should use the robots in early game, because power is scarce in early game.
- But in mid game, the robots shows excellent in far-from-base missions. For example: oil biome, space.
- It’s like the AI coming into this era. The era I’m living in.
- When robots are doing their capabilities well, the human should as well.
- My thoughts from ((69bb6817-761c-4303-afdb-2bc2af90b150))
Meaning of 1on1 meetings with manager
- Chance to nurture the team/organization’s human resource.
Recently I realize the ones who treat their work on company like their own thing is the successful one.
- That said, “làm việc bằng cái tâm”.
- Because when you treat it as your work, non-of-my-business does not exist.
- Have better responsibility, better empathy, better quality.
- Quality in everything.
Tasks
Partly today
- DONE Ingest full Calendly data into BigQuery
Context
- This project is to ingest full Calendly data into BigQuery
- Currently, there are demo and onboarding calls are ingested, but not 1-1, case study, customer success calls.
- This project is suspended for a long time ago.
- I am the PIC. But now I forget almost everything about it.
- Let’s better treat this project as if I start over.
Trigger
- Growth team needs.
- Q: Growth team needs call data for what use case?
- Sales rep performance.
- Categorize leads (call-first or trial-first).
- Q: Growth team needs call data for what use case?
- Although not high priority.
- Since I’m coming back from higher priority projects (AI benchmarking and Add2Cart), it’s time to do this.
- Growth team needs.
At Holistics, we actually have another data source for call recordings, which is Clari/ReadAI.
- This is a project that Thuan is actively working on it.
- Q: Am I overlap his work?
- Ampcode
- Let’s firstly remind the purpose / role of Calendly data within the big picture of our data platform.
- Q: What is Calendly used for?
- A:
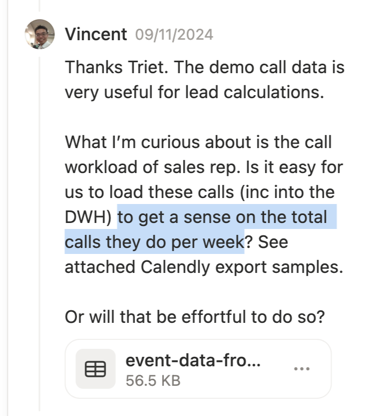
- Counting the number of calls per sales reps => Vincent wants to know how many calls each rep take a week?
- https://media.secondbrain.lelouvincx.com/2026/03/66b02fb3a32b691cee0255245b5d988f.png
- Ingredient for calculating sales motion (call-first / trial-first).
- A:
- Q: Who use?
- A: Growth team (Vincent). He needs visibility into rep activity (calls made, follow-ups done).
- Q: How important?
- A: Medium-low.
- There’s a known limitation that compounds the challenge: Calendly does not auto-mark meetings as no-shows, and Hubspot’s “Last Meeting Interaction” is unreliable because it requires reps to manually mark meeting outcomes as “Completed.”
- Q: Does it overlap on anything with ReadAI project?
- A: For scheduled calls, Calendly is more trusted than ReadAI because there are some calls not being recorded or private, that ReadAI cannot ingest.
- Q: What is Calendly used for?
Plan
- Define ingestion schema, what we need.
- The current pipeline is Calendly => Zapier => Google Sheets => Data Import => BigQuery
- This only captures created events, for cancelled/rescheduled events we need another Zap for this
- This has only 400 events, while in total we have 4438 events (since 2016)
- Hard to control/debug when sync error
- Suggest a better tool to ingest Calendly: either Prefect / Airbyte.
- Here is the whole schema taken from openapi: https://dbdiagram.io/e/69d61041808962968445981c/69d62f0f8089629684479d06
- Required data from these tables:
event_types,events,cancellations,invitees,event_guests,users,invitee_questions_and_answers - These’s
event_typesdata that cannot be extracted from Zapier. - Currently, to prevent blocker, I’m using Fivetran to sync data. In the future we can upgrade Airbyte and switch, nothing would breaks since we already know the schema from official Calendly API.
- Waiting for anh Dong to review document and code. There is some files I don’t like in the code but it’s fine for now.
- OpenAPI spec: https://stoplight.io/api/v1/projects/calendly/api-docs/nodes/reference/calendly-api/openapi.yaml
- When do data pipeline, ingesting phase, should find for something like an openapi like this for source schema reference. This is important because when the source API change, we have reference to update our data code accordingly.
- Anh Dong has reviewed, my job to answer reviews.
- Re-model into fact bookings and dim event, while fact booking’s grain = event x invitee x rep.
- PR approved https://github.com/holistics/dbt/pull/853, next step is to run dbt models and continue in Holistics BI.
- Update reporting layer:
- Model
- Dataset
- Dashboard
Layer Model Alias Source src_calendly(7 Fivetran tables) +src_gsheets.calendly__event_type_categories(mapping seed)Staging stg_calendly__events,stg_calendly__event_invitees,stg_calendly__event_hosts,stg_calendly__event_guestsDomain dom_calendly__bookings(grain: event × attendee × rep)Mart mart_growth__calendly_bookings(view,fct_calendly_bookings)Fact table Mart mart_growth__calendly_events(table,dim_calendly_events)Dimension Deprecated mart_growth__demo_calls,mart_growth__onboarding_calls,mart_core_business__demo_call_bookings,dom_calendly__demo_call_bookings,dom_calendly__onboarding_call_bookings— allenabled: falseFixed mart_core_business__sales_leads— now joinsdom_calendly__bookingsdirectly onattendee_email_domain
((69a2a1cc-fc1f-4802-ba56-48183fa9e9a5))
TODO Think about applying AI into resolving #data-ops-bot issues (data pipelines)
What we do:
- Pick a task
- Resolve it manually
- After done, write a very detailed guide (so that a guy with minimal knowledge about Holistics can still resolve himself)
- Put it to agents to try
- Loop
After that, we can materialize it as a skill.
Plug it into the agent, tag on slack whenever a bug appears.
Improve it incrementally.
Issues in ((69b3d030-98dd-450d-88d8-e00c1c322c59)) can be resolve easily and fast.
Better way to do: Delegate to juniors: Thuan / agents.
- For agents:
- Write a very detailed step-by-step guidance for the task.
- Let the agent attempt.
- Note down learning points => improve => release the first version of agent skill.
- For Thuan (will need advice here, here is just a simple process I come up with):
- Pair programming.
- Observe how he solves the problem.
- Note down teaching points, learning points.
- For agents:
Done
- DONE Support Sasha mybacs
DONE Support Sasha mybacs
- relative_period does not support future time?
- Since AQL doesn’t support a dynamic rolling window where N changes per row, We split this into 4 separate conditional demand metrics using
case+where, then combine them. Each metric contributes demand only for rows matching its product group AND whose month falls within the correct future window.
DONE Add
shadcn/uiskills to speed up frontend development
{kind=link}
{kind=link}